

Data has become the operating system of modern enterprises. From AI models and customer analytics to regulatory reporting and real-time decision-making, organizations now rely on data pipelines as critical infrastructure rather than back-office utilities. Yet as data volumes explode and architectures become increasingly distributed across cloud, SaaS, and edge environments, traditional perimeter-based security models are failing.
Recent industry analyses consistently show that data breaches are no longer primarily caused by external hackers breaking through firewalls. Instead, they stem from compromised identities, misconfigured services, insecure APIs, and excessive privileges inside trusted networks. In data engineering specifically, pipelines often move sensitive information across multiple systems, making them high-value attack paths.
This reality has propelled the adoption of Zero-Trust principles, a security philosophy based on the assumption that no user, system, or network should be trusted by default.
Zero-Trust Data Engineering applies these principles to the design, development, and operation of data pipelines so that security is embedded into every stage of the data lifecycle, ingestion, processing, storage, access, and sharing.
Rather than bolting on controls after deployment, organizations are now pursuing secure-by-default pipelines that:
Continuously verify identities and access
Minimize blast radius through least privilege
Protect data in motion and at rest
Monitor behavior for anomalies
Enforce governance automatically
For technology leaders, the shift is not optional. It is foundational to enable AI adoption, regulatory compliance, multi-cloud operations, and digital trust.
Industry Overview & Key Concepts
The Rise of Data as Critical Infrastructure
Enterprises today operate hybrid ecosystems spanning on-premises systems, cloud platforms, partner networks and consumer devices. Data flows across these environments continuously.
Key drivers increasing risk include:
Cloud-native architectures
Microservices and APIs
Real-time streaming systems
AI/ML pipelines
Third-party integrations
Remote workforces
Traditional network perimeters cannot protect such fluid environments.
What Is Zero-Trust?
Zero-Trust is built on the principle: “Never trust, always verify.”
Core pillars include:
Identity-centric security
Least-privilege access
Continuous authentication and authorization
Micro-segmentation
Comprehensive visibility
Automated response
What Is Zero-Trust Data Engineering?
It extends Zero-Trust to data systems by securing:
Data ingestion channels
Processing environments
Storage layers
Access interfaces
Data sharing mechanisms
Security becomes an intrinsic property of pipeline design rather than an external control.
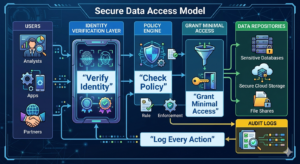
Core Framework: Secure-by-Default Data Pipeline Architecture
A Zero-Trust data pipeline is designed as a layered system where each stage independently enforces security.
Trusted Data Ingestion
Secure ingestion prevents malicious or unauthorized data from entering the ecosystem.
Key controls:
Source authentication
API security
Data validation and sanitization
Rate limiting
Secure transport protocols
Identity-Aware Processing
Processing environments must verify both workloads and operators.
Controls include:
Workload identity management
Container security
Secure execution environments
Ephemeral credentials
Runtime protection
Encrypted Storage & Data Protection
Data should remain protected even if storage systems are compromised.
Techniques include:
Encryption at rest
Key management systems
Tokenization and masking
Differential privacy for analytics
Immutable storage options
Fine-Grained Access Control
Zero-Trust mandates precise authorization based on context.
Approaches include:
Attribute-based access control (ABAC)
Role-based access control (RBAC)
Policy-based governance
Row-level and column-level security
Just-in-time access provisioning
Continuous Monitoring & Analytics
Security requires real-time visibility into behavior.
Capabilities include:
Audit logging
Anomaly detection
User behavior analytics
Threat intelligence integration
Automated incident response
Key Challenges Organizations Face
Adopting a Zero-Trust approach in data engineering is not merely a technical upgrade, it requires rethinking architectures, processes, and organizational mindset. Many enterprises encounter structural, operational, and cultural barriers while transitioning from traditional security models to a continuously verified environment. Understanding these challenges helps organizations plan realistic implementation strategies and avoid costly setbacks.
Legacy Systems and Technical Debt
Older data platforms were not designed for modern security requirements. They often lack fine-grained access controls, advanced encryption, API-driven integration, and identity federation capabilities. As a result, integrating Zero-Trust principles into such environments requires extensive reengineering, workarounds, or platform modernization, making the transition complex and resource-intensive.
Data Silos Across Hybrid Environments
Enterprise data typically resides across multiple clouds, on-premises systems, and SaaS applications. This fragmentation makes it difficult to maintain consistent governance, visibility, and control. Without unified policies and monitoring, enforcing Zero-Trust across distributed data ecosystems becomes challenging.
Operational Complexity
Zero-Trust introduces new operational layers, including identity lifecycle management, policy administration, continuous monitoring, and incident response coordination. If these processes rely heavily on manual effort, they can overwhelm security and engineering teams, slowing down operations and increasing the risk of misconfigurations.
Performance Concerns
Additional authentication checks, encryption, and monitoring can introduce latency, particularly in high-throughput or real-time analytics pipelines. Organizations must balance strong security with performance optimization to maintain user experience and business agility.
Cultural Resistance
Teams accustomed to broad or open access to data may view Zero-Trust controls as restrictive or productivity-reducing. Successful adoption requires leadership to communicate that stronger security safeguards innovation, protects business value, and enables sustainable growth rather than hindering it.
Best Practices & Implementation Strategies
Implementing Zero-Trust effectively requires a proactive, design-led approach rather than reactive fixes. Organizations that embed security into architecture, governance, and operations from the outset can achieve stronger protection with lower long-term costs and complexity. The following practices support a scalable and resilient implementation.
Design Security into Pipelines from Day One
Building security controls directly into data pipelines ensures consistent protection throughout the data lifecycle. A secure-by-design architecture prevents vulnerabilities that often arise when controls are added after deployment.
Adopt Data-Centric Security
Instead of relying solely on network or infrastructure defenses, organizations should protect the data itself through encryption, classification, masking, and access policies. This approach ensures security persists regardless of where the data travels.
Implement Least Privilege Everywhere
Users, applications, and services should receive only the minimum permissions required to perform their tasks. Limiting privileges reduces the attack surface and prevents misuse of excessive access rights.
Automate Governance
Manual security controls cannot keep pace with modern data environments. Automation enables consistent policy enforcement, faster incident response, reduced human error, and continuous compliance with regulatory requirements.
Use Strong Encryption and Key Management
Comprehensive encryption both at rest and in transit protects sensitive information from unauthorized access. Centralized key management ensures keys are securely stored, rotated, and governed, minimizing fragmentation and risk.
Establish Comprehensive Observability
End-to-end visibility across data pipelines allows security teams to detect anomalies, investigate incidents, and verify policy effectiveness. Continuous monitoring transforms security from reactive defense to proactive risk management.
How Round The Clock Technologies Delivers Zero-Trust Data Engineering
Round The Clock Technologies enables enterprises to build secure, scalable, and future-ready data ecosystems through a comprehensive Zero-Trust approach.
Strategic Consulting Approach
The company begins with a holistic assessment of:
Data architecture
Security posture
Regulatory requirements
Business objectives
Risk exposure
Experts design a tailored roadmap aligned with organizational priorities.
Implementation Methodology
A structured delivery framework ensures successful adoption:
Discovery and risk analysis
Architecture design
Technology selection
Secure pipeline implementation
Testing and validation
Continuous monitoring and optimization
Technology Expertise
Round The Clock Technologies possesses deep expertise across modern data platforms, including:
Cloud data warehouses
Streaming architectures
Data lakes and lakehouses
Containerized environments
API ecosystems
Identity and access management systems
Engineering Capabilities
Dedicated engineering teams implement:
Secure ingestion frameworks
Policy-driven access controls
Encryption strategies
Observability platforms
Automated governance solutions
Tools, Platforms, and Frameworks
Solutions leverage industry-leading technologies across:
Cloud providers
Security platforms
Data orchestration tools
Monitoring systems
Compliance frameworks
Industry Experience & Domain Knowledge
With experience across sectors such as finance, healthcare, retail, and technology, the company understands regulatory nuances and operational realities.
Enabling Scalability, Performance & Transformation
Round The Clock Technologies ensures that security enhancements do not compromise performance. Architectures are designed to support:
High-volume data processing
Real-time analytics
AI/ML workloads
Global operations
Future scalability
By embedding Zero-Trust principles into the data foundation, the company empowers organizations to innovate with confidence while maintaining resilience and compliance.